
|
|
|
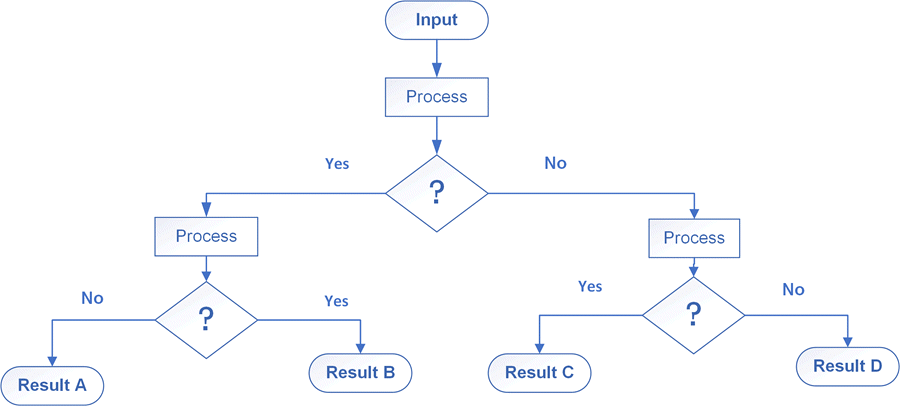
Some of the earliest real-time decision support were based on decision trees, where inputs to the system were used to traverse a fixed tree with conditional rules applied at each level of the tree.
These are still used where the size of the decision tree is limited, the outcome of each decision process can be expressed in a yes/no decision, and the decision flow can be hard coded, such as with a limited rule-set within a MilramX intelligent agent.
Applications today include ladder-logic programming of PLCs (Programmable Logic Controllers) as well as SCADA (Supervisory Control and Data Acquisition) systems used in process control and some algorithms within self-guided cars.
The decision tree paradigm breaks down, as the code becomes impossible to manage, debug or easily modify when:
These days, building a decision support system is an iterative process, which requires adding and changing decision rules and processes in an "Agile" software development process.
Except in simple cases, such as within intelligent agents, decision trees do not lend themselves to this programming style and are much more effective with the older "Waterfall" development methodology where all the decisions are hard-coded based on a fixed specification.
Return to "Why Intelligent Agents?"
|
Copyright © 2021 Milramco LLC |
